




Significance of categorical feature
Categorical (Nominal) features are part of almost every dataset. These features need a separate step while pre-processing the data i.e. Encoding.
Key reasons for this encoding are -
- Almost every Library implementation need Features in numeric form even if the interpretation is Nominal
- Almost every Algorithm works only with Continuous features (Tree, Naïve Bayes can be few exceptions)
- You may achieve a better result and/or smaller feature set with an appropriate encoding
When you try to encode, you may face any of these situations -
- High Cardinality of the Feature e.g. Zipcode
- Feature gets new value in test data
- Feature values are Ordered e.g. Size of apparels (XS, S, M, L, XL etc.)
- Features may be Cyclic e.g. Days on Month
Based on the above need and list of scenarios, we can have multiple ways to deal with all. Let's dive into each one.
Different approaches
1. Label encoding
Label encoding is the minimum level of encoding that we can perform. It only solves the first problem i.e. Satisfy the Frameworks requirement This is simply mapping the Feature value to numbers i.e. 1-N
e.g. [Cat, Dog, Elephant ] —> { cat : 1, dog : 2, elephant : 3 }
Challenge with Label Encoding
While this has satisfied the Framework but it has created something which will deceive many Models e.g. LinearRegression, Neural Networks. The simple reason is that these models will treat the feature as continuous and use the information that "2 time Cat is a Dog etc." which is an incorrect pattern to learn.
This is something that we do not want! So, let's move to One-Hot Encoding.
2. One Hot Encoder
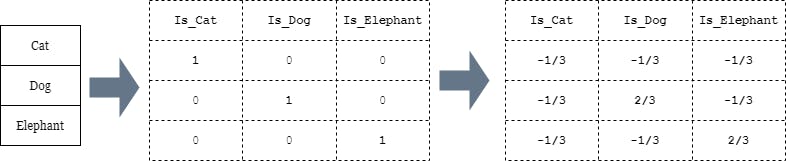
OneHotEncoding is a technique where we split the Feature into one binary-feature for each of the values for the feature in the main dataset.
e.g. [Cat, Dog, Elephant ] —> { cat :[1, 0, 0],dog: [0, 1, 0], elephant :[0, 0, 1] },
One-Hot imply one of the bits is Hot(1).

Image explanation
Each value becomes a new Features indicating the presence of that values i.e Is_CAT==1 imply the value of original feature is CAT for that data point
Interpretation of OHE feature
Unlike LabelEncoder which doesn't make a guaranteed sense to all the Models, OHE can guide the Model to deduce some pattern in the direction of the right Target.
If we assume the underlying Model as LinarRegression, the Coefficient of Is_Cat will indicate the change in the mean output when the Feature changes from 0 to 1 i.e. No_Cat to Cat (see below depiction)
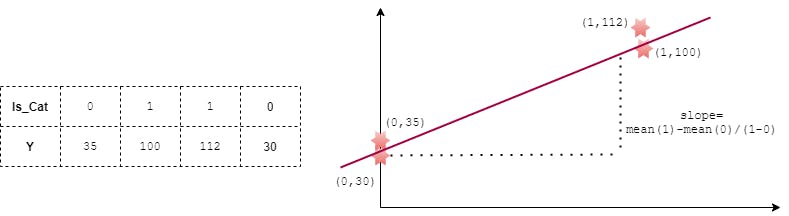
Challenge with One-Hot Encoding
1. It will add as many dimension as the number of unique values i.e. can become very challenging with Feature having high Cardinality
2. Not very efficient for models like Neural Network which works better on continuous data
3. Hashing, BaseN, Binary
These techniques are very handy when dealing with feature with very high dimension
Binary encoding is the simple binary representation of Label encoded data
e.g. [Cat, Dog, Elephant, Fox ] —> { cat :[0, 0], dog: [0, 1], elephant :[ 1, 0], fox: [1, 1] }
BaseN is the approach to generalize this to any base i.e. Octal ⇒ 8 Values/bits
Hashing encoding is done by mapping each value to a new value using a hash function.
[Hashing function] and related concept are quite prominent in computer science.
These encodings have similar challenges as that of Label encoding i.e. absence of a meaningful representation of Feature.
It can be used with sparse data in a very high dimensional space i.e. Collaborative filtering. Check this paper [Link].
In a common ML problem, these techniques are not very helpful
4. Count based
Count encoding means that for a given categorical feature, replace the names of the groups with the group counts.
This encoding can work when the Feature count is having a good correlation with the Target. e.g. Country name and sample data of any disease.
More the infected people more is the positive sample of that country in the dataset.
Supervised vs Unsupervised
Methods till now were all Unsupervised i.e. didn't involve the Label. But we can have techniques that use the Labels too
5. Target-based encoding [Supervised ]
Target encoding is a family of techniques where we use the Target in the encoding process. What it means, we are getting guidance from the Target itself.
The most simple approach can be to use the mean/median of the target for the particular value of the Feature.
The most commonly used approach is as suggested in this paper [ Link ]
It basically tells us to map the estimated probability for the value i.e.
cat —> (count of cat for Y==1) / (Total count of Cat),
For a regression setup, the average value should be used. In the case of multi-Class, there will be m-1 encoded features i.e. each representing the encoding for one Y(class)
But this mapping is not used because the those values which have have very few samples for positive class will be misrepresented in this setting.
A prior probability is calculated = *(Count of Cat) / (Sample size)*
Then, both the mapping is blended with a parameter i.e. $$ \lambda * posterior\_estimate + (1 -\lambda) * prior\_estimate $$
Lambda is between [0-1] and is mapped to the count of each value. What it means that for values having high count the posterior_estimate will dominate and for values having low count the prior_estimate will dominate
Below table depict a target encoding for Countries on Income census dataset [ Link ]
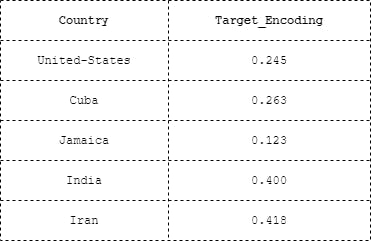
Target encoding has a few key benefits
- It only creates one dimension in the Feature set
-It can work in almost every scenario i.e. ordinal, High Cardinal, Cyclic etc.
The risk that is attached
to this approach is of data leakage which may result in highly optimistic results on the train set. A suitable cross-validation approach must be used with this encoding scheme.
6. Entity embedding [Supervised ]
Entity embedding is another Supervised technique that utilizes a Neural Network to fit the OHE version of the feature to the target and the weight of the Network is used as the encoding.
We have a separate blog on this technique, please check it. [ Link ]
7. Special scenarios
a. Ordinal Feature
Ordinal feature are those where the values have an underlying order esp. when that order has a similar impact on the Target e.g. Education level
Encoding it with a simple approach i.e. OHE will do the minimum work but the Model will miss the information that is mapped to the Order of the values.
As in every case, Target encoding can be tried here too.
Another approach for Ordinal encoding is using "Orthogonal Polynomial Contrast encoding".
Contrast encoding is a family of techniques to encode categorical features. The key difference with OHE is that it does not use [ 0 ] as a reference value. The issue with using 0 as reference value is that the Intercept of the Target is the mean of the reference value and all the parameter is expressed in terms of the deviation with the reference value. Ideally, it should be with the mean of all values. Read here [Link]
Polynomial contrast is the extension to add an underlying trend in the mapping. The trend can be Linear, Quadratic, Cubic Or higher level polynomial. e.g.
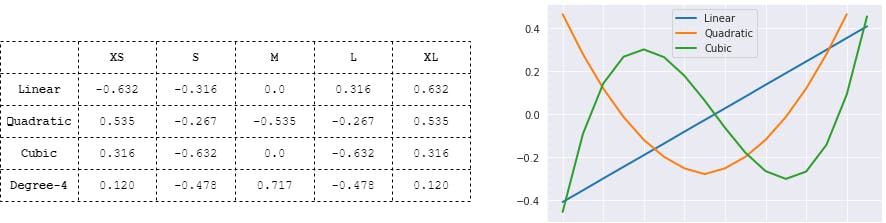
So, each poly degree will add one dimension. Though not necessarily all will be useful.
Individual features are orthogonal to each other. This is important so that each must add unique information as a feature. Individual values are not important. All the values just satisfy the required conditions i.e. Following the polynomial, Orthogonal (i.e. dot product =0), Sum=0.
The assumption here
is that the values(factors) are equally spaced. The reason for that is because all the values are equally-spaced consecutive values on the polynomial curve. What it means is that if we encode only these 3 factors which are not consecutive i.e. XS, S, XL, this encoding approach will be incorrect.
b. High Cardinal Feature
When a particular feature has too many values(factors) than using the default OHE can add a lot many dimensions which is undesirable. You may take these approaches -
- Remove feature value which has a very small frequency
- Try Target encoding
- Try Entity embedding
c. Less Frequent values
When the values of the Feature have very little frequency, it means it has little importance to predict the target pattern. In such a scenario, you may,
- Club such feature into a consolidated feature
- Remove a few of these which are below a Threshold count
d. New values post-training
If a new value is encountered after training, it might break the Model if not properly handled before-hand.
One approach would have "Other" as a value to map such value. All though it will not help in the pattern mapping but can work as a "Catch" statement. Ideally, you must review such a scenario in the purview of the data domain i.e. Why a new value arrived.
To handle this situation in your Train-Test split, you can
- Manually verify that each Categorical feature has at least one value of each factor. If not add one record post the split and prior to the encoding.
- Use the
categoriesparameter ofscikit-learn OHEto provide the list of all possible value before-hand
e. Cyclic values
A cyclic feature is a feature whose values are connected at the end e.g. Days of a month, here 30 is equally closer to 01 and 29.
Hence, the encoding technique must have this pattern in the resulting mapping. Target encoding and Entity embedding can inherently learn this but other techniques might miss this if not done explicitly.
In this case, we can map the values to a sine and cosine curve (in an approach similar to the polynomial degree mapping).
The only reason we need both the curve is that just having one of the two can result in the same encoding for two values e.g. sine(45)=sine(135). Read this SE Answer [ Link ]
feat_sine = sin((2*pi)/30*day_of_month)
feat_cos = cos((2*pi)/30*day_of_month)
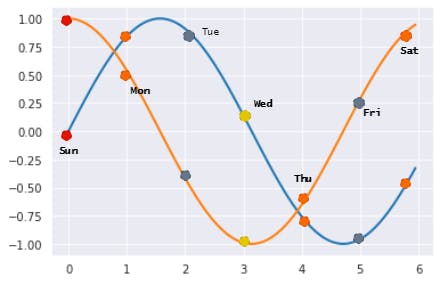
The above plot is a logical depiction of how the two points will represent each day of a week. In a similar manner, we can create 30 slots for days of Month.
Although this can solve the problem of values being cyclic but not necessarily it will be the best encoding.
The code
Using the above explanation you can easily do all the required encoding. But you don't need to do so. category_encoders from scikit-learn.contrib has got all the required encoding. Below code snippet is a sample example of how to use this Libary. Please check its documentation [ Link ]
!pip install category_encoders # Install the Library
import category_encoders as ce # Import the Library
encoder = ce.TargetEncoder() # Create Class for Target Encoder
x_train = encoder.fit_transform(x_train, y_train) # fit_transform
x_test = encoder.transform(x_test) # transform
Other good things about this Library is that
- It follows the scikit-learn standard convention for fit transform.
- It handles the backend issue that you face with scikit-learn OHE e.g. not allowing float etc. It returns you a clean Dataframe with all the columns properly named.
Few remaining questions
i) Do we need encoding for Tree-based Model
The way the Tree-based model works, it doesn't matter a lot for it to need OHE Or any other encoding. It simply works with Label encoding. In fact, it will be a bit faster with Label encoded data.
ii) Do we need to always map (K-1) feature during OHE for K factors
This is again, a very frequently asked question. Please check my answer at SE. [ Link ]