


Understanding and Coding Semi-supervised Machine Learning
Active Learning, Weakly supervised


Introduction
Hello, AI Enthusiast! In this post, we will learn about another handy but not readily available Machine Learning technique, i.e. Semi-supervised Learning. The Foundation of this concept is around a family of a concept whose goal is to solve one of the most prevalent challenges of Machine Learning i.e. availability of Labelled data. There are multiple terminologies around this idea i.e. Semi-supervised, Weakly-supervised, Active Learning etc.. So first of all we will define these.

Different approaches have been depicted in the above image. If we try to infer from the depiction we can say that Semi-supervised, Weakly supervised and Active learning are the approach to get the supervised modelling done with a lesser cost and effort of Data labelling.
Supervised Learning - This is the defacto ML technique. In this approach, we use has 100% accurately labelled data. Definitely, labels can be inaccurate but we assumed it no so. Typical ML algorithm i.e. Regression is an example of this type of Learning
Un-supervised Learning - In this approach, we train the model with unlabelled data. ML algorithm i.e. CLustering,Anomoly detection are the examples of this type of Learning
Semi-supervised Learning - This is the topic of this post. In this type of learning, we use both Supervised and Un-supervised learning. With the Un-supervised approach, we try to label the unlabelled dataset using its proximity(Not limited to just one technique) to the labelled dataset's classes. Then we apply the Supervised Learning to the full dataset.
The key assumption will be - The points that are near-by Or sharing the same Cluster belongs to the same Class. The data points as shown in the below depiction might not work in a typical Semi-supervised approach.
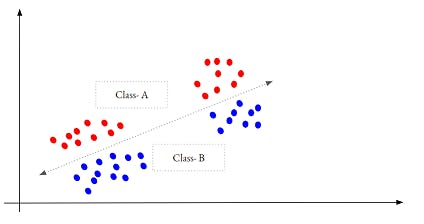
Weakly-supervised Learning - This itself is a family of approaches. The main idea is not to reply to Complete and accurate Labels. So, Labels can be inaccurate too. Semi-supervised is then a special case of this approach.
"....Weak supervision is a branch of machine learning where noisy, limited, or imprecise sources are used to provide supervision signal for labelling large amounts of training data in a supervised learning setting..." [ Wikipedia ].
May read this paper to dive deep into the approaches A brief introduction to weakly supervised learning
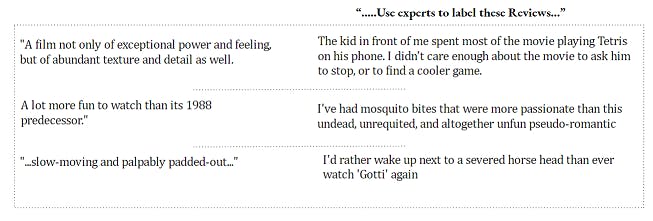
Active Learning - * This is not a new learning approach. This is a way to boost the Semi-Supervised Or Weakly-supervised approach using the input of Subject matter Experts in the most optimized way. The underlying idea is that rather than asking the domain experts to label all the data, we better ask them to Label the most difficult(for the Machine) ones. For the human, both cases will take almost the same effort. Check the contrastive examples of Movie-Reviews in this depiction
Dataset and approach
We will use the MNIST digit dataset Link.
We have used this smaller version of the MNIST(784 Features) to avoid the dimensionality reduction and extra computation but the concept will remain the same and work on that too.
Our Approach will be -
- Build a Classifier with 75% of the dataset for baseline score on the 25% test dataset
- Build another Classifier assuming we have only 5% of the data as Labelled and get the score on this. Our goal is to make this score almost equal to the initial baseline using Semi-supervised and Active Learning.
- Build a KMeans Cluster with all the data. Assign the CLASS of each Cluster's centre to all the points in that Cluster [Semi-supervised]. Get the new score
- Pick the incorrect ~7.5% of the records and get its correct CLASS[Active-Learning]. We already got the class but let's assume a Human will do so.
- Get the final score
Let's code it
# skipping the data load part
from sklearn.model_selection import train_test_split
x_train,x_test, y_train,y_test = train_test_split(x, y, test_size=.25, random_state=1)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(max_depth=6,min_samples_leaf=5)
model.fit(x_train, y_train)
model.score(x_test, y_test)
Result
0.96
This is our First baseline score
Now, get 5% of the training data and assume the other 95% as unlabelled. Calculate the new score. Remember, we will always predict the score on initial test data which will remain untouched through-out.
x_train_label,x_train_unlabel, y_train_label, y_train_unlabel = \
train_test_split(x_train, y_train, test_size=.95,stratify=y_train, random_state=2)
model = RandomForestClassifier(n_estimators=20, max_depth=5,min_samples_leaf=2)
model.fit(x_train_label, y_train_label)
model.score(x_test, y_test)
Result
0.76
This is our baseline with 5% labelled data
Now, Let's build a KMeans Cluster for all the training data. We will assume we don't have labels for these data.
from sklearn.cluster import KMeans
def create_cluster(k = 2):
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=k)
kmeans.fit(x_train)
return kmeans
kmeans = create_cluster(k=50)
Code-explanation
K=50 is based on prior knowledge. You will have to create a plot of K Vssilhouette_scorei.e. the elbow method
Let's do the Semi-supervised part. We will get the Center of each Cluster. Then predict the Digit CLASS for each centre. Assign that CLASS to all the members of the centre
centroid_clusr = kmeans.predict(kmeans.cluster_centers_) #1
centroid_digit = model.predict(kmeans.cluster_centers_) #2
cluster_digit_map = dict(zip(centroid_clusr,centroid_digit)) #3
y_pred_unlabel_clust = kmeans.predict(x_train_unlabel) #4
y_pred_unlabel_digit = list(map(lambda x: cluster_digit_map[x], y_pred_unlabel_clust)) #5
x_train_new = pd.concat([x_train_label,x_train_unlabel], axis=0) #6
y_train_new = np.concatenate([y_train_label, y_pred_unlabel_digit])
model = RandomForestClassifier(max_depth=7, min_samples_leaf=6)
model.fit(x_train_new, y_train_new)
model.score(x_test, y_test)
Code-explanation
#1 - Get the Cluster Id for all the centers
#2 - Get the Digit Class for all the Cluster centers
#3 - Create a dictionary mapping for above two
#4 - Predict the Cluster Id for our unlabelled data i.e the 95%
#5 - Get the Digit CLASS for the above using the map. This will be the "Y" of our unlabelled data i.e the 95%
#6 - Concatenate the unlabelled to the Labelled
Get the score on the above data as our improved score i.e. Semi-Supervised learning.
Result
0.8688888888888889
Let's do the Active Learning step. We will infuse the correct label for the worst ~100 records of the unlabelled dataset i.e. the 95%. Ideally, we may get this done with an expert but since we already got all the labels, so we can simply pick that form the y_train.
unlabel_proba = np.max(model.predict_proba(x_train_unlabel), axis=-1) #1
index_list = []
for id,elem in enumerate(y_train_unlabel): #2
if elem != y_pred_unlabel_digit[id] and unlabel_proba[id] > 0.425: #3
index_list.append(id)
y_pred_unlabel_digit[id] = elem #4
x_train_new = pd.concat([x_train_label,x_train_unlabel], axis=0)
y_train_new = np.concatenate([y_train_label, y_pred_unlabel_digit])
model = RandomForestClassifier(max_depth=6, min_samples_leaf=5)
model.fit(x_train_new, y_train_new)
model.score(x_test, y_test)
Code-explanation
#1 - Get the probabilities of unlabelled dataset
#2 - Loop on the true unlabelled dataset(y)
#3 - Find those which were predicted incorrectly with a high confidence
#3 - 0.425 was chosen because we wanted ~100 records
#4 - push the correct label into our unlabelled dataset
Get the score on the above data as our further improved score i.e. adding Active learning.
Result
0.9355555555555556
Conclusion
Great, we reached almost 94% with only 5% of initial data and then another 7.5% as part of Active learning infusion. We didn't try too much on parameter tuning.
We must be mindful of the fact that the above percentage, choice of Clustering technique etc. will differ according to the dataset.
You may try the exercise,
- On the full MNIST dataset
- Visualize the 3 sets of digits i.e. all, labelled, labelled in the last step with t-SNE