




Introduction
Hello friends, in this post we will learn about one of the most versatile ideas in the Artificial Intelligence field i.e. Word-Embedding. The other high-leverage ideas are Gradient Descent, Pre-trained models and recently "Transformer architecture.
The idea started with the thought of representing the texts as a Vector. Representing texts using n-dimensional vector is something we have done from the very first lesson of ML i.e. One-Hot-Encoding. In a very formal definition, OHE too is a Vector representing the underlying words.
Using OHE, we have modelled our data and achieved a decent result.
We can use some other techniques to achieve this task e.g. term-frequency, tf-idf etc., the way we did in the first post of this series.Check that Here
Challenges with OHE, Simple Encoding
While the simple encoding technique is good for basic tasks but it is a sparse approach of encoding and these techniques result in a lot of Dimension for a large word corpus.
This will cause two major problems for any ML algorithm,
- It will create high dimensional sparse (a lot of zeroes) data
- It loses the semantic information of the underlying text i.e. distance between Related, Similar words is the same as between unrelated words.
Check this simple depiction for the two scenarios,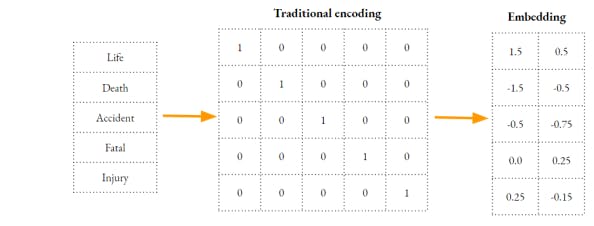
Now we understand the idea and the need for such an encoding approach i.e. Dense vector. Let's understand the way we can achieve it.
How to do it
Let's check the depiction shown below,

We follow the following steps to learn the embeddings of the words,
- Decide the dimension(N) of the embedding. This is a Hyper-parameter
- Assume the first layer as the embedding i.e. should have MxN Neuron. M is the number of unique words.
- Pass the input as OHE of the words. In short, only those weights will be updated in the backpropagation.
- Post the training completion, the weights matrix will represent the Embedding Matrix.
But we don't need to do all these setups explicitly. We can simply use the Keras embedding layer and it will take care of all these inner workings.
Please check the previous post of this series Here where we have used the Keras embedding layer and explained the parameters in details.
With that, we have our words encoded with the appropriate context provided by the dataset. It will smoothen the training process because learning is a dense vector.
The only thing that has to be noted here is that we can't do much with the embedding that we got in the end. Since we were actually interested in the Models accuracy which we got at the completion of the training and the embedding too took the whole training cycle.
What I meant is that the reusability was missing.
Another aspect is that it was trained in a pure supervised manner, you can't always expect to have a text corpus with some type of labels available.
Good news is that if we have a similar context then you can reuse the final embedding that we got from the previous training. For example, we trained our model on sentiment analysis, which means we may use it for another type of similar system i.e. Product review.
A much better news is that we have got an even better solution, There are multiple available word-embedding that are trained on a huge volume of the dataset which can be used in text analysis tasks.
Pre-trained models
While you can train your own model to get the embedding every time but this will have two obvious challenges -
- You can't have a sufficiently large corpus to train the model to learn the embedding
- If you have a large enough corpus, then you will not prefer to invest so much computational cost every time.
Pretrained word embedding map is the solution to both these problems, obviously with a trade-off.
Pretrained word embedding models are models that have been trained on a very large Corpus e.g. Wikipedia to generate the embeddings of each word.
While such an approach will give us a sufficient generic embedding of each word but it lacks a specific context knowledge e.g. Medical text. This is the Trade-off.
Another useful aspect of pre-trained embedding is that these are trained with an end goal in mind i.e. create embedding, so these model are optimised for computation.
Although the high-level approach is similar to the depiction we saw in the previous section but these models use some alternative approaches instead of a Deep Neural Network to avoid the huge computational cost. A Deep Neural Network is not very computation effective solution.
Let's quickly review a few of the famous Pre-trained models,
word2vec - Word2vec model became one of the most famous pre-trained embedding models. It learns the relationship of all words by looking at them in small sliding windows and then train the model by applying a supervised approach. This approach (i.e. using the vocab as data and labels both) will be common for all the pre-trained models.
Let's check this depiction, It has two different algorithms available as options to the user i.e. Continuous BoW(Bag of Words) and Continuous Skip-Gram.
It has two different algorithms available as options to the user i.e. Continuous BoW(Bag of Words) and Continuous Skip-Gram.
In CBoW, the model is fed with past "K" words and future "K" words and trained on the prediction of the centre word. K is a hyperparameter. In the image above, K=3.
Bigger K will have better context but will add to the computational overhead.
In the case of continuous skip-gram, it is done the other way round. The model tries to predict the contextual past and future words using the centre word.
If you want to dive deep into the calculation, check out this paper which was written just to explain word2vec since the original paper is not very easy to comprehend.GloVe - GloVe stand for Global vector. It was developed as an open-source project at Stanford. The way it differs from word2vec is that it tries to learn a global pattern of the corpus, unlike the word2vec which focussed on local windows.
It used the co-occurrence count of each word with respect to other words. It calculates the probability of each word to be as a co-occurrence word to any other word. Check this table from the official website,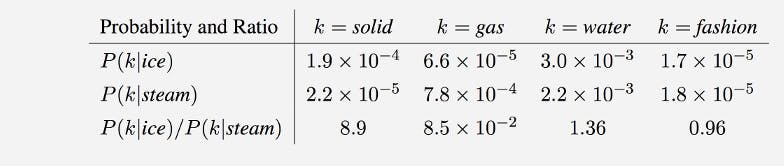 It then tries to learn a vector such that the word is near to another word with a high probability of co-occurrence but distant to a word with a low probability of co-occurrence. In the above depiction, "Solid" is close to "Ice" as compared to "Steam".
It then tries to learn a vector such that the word is near to another word with a high probability of co-occurrence but distant to a word with a low probability of co-occurrence. In the above depiction, "Solid" is close to "Ice" as compared to "Steam".
If you want to dive deep into the calculation, check out the originalpaper
Embeddings meaning and Biases
Embeddings align the word in an N-dimensional space according to the context learnt from the training corpus. We can easily visualize the same in 2-D space by either dimension reduction or using the appropriate visualization technique. We will do this exercise in the next post.
Let's see this examples which is not just showing the neigbhourghood of words but also a temporal sense i.e. the neighbourhood changes. This can happen if the contemporary corpus i.e. Newspaper, Social Media changes the way it interprets particular words. This is a type of concept drift.
 Image Credit - Sebastian Ruder's Blog
Image Credit - Sebastian Ruder's Blog
Also, check this embedding created on a corpus of Game of thrones. It has the top five words near to the word King and Queen.
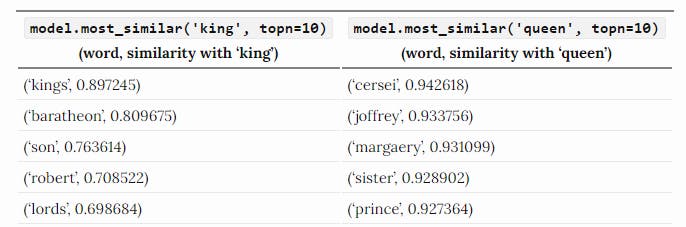 Image Credit - Lilian Weng's Blog
Image Credit - Lilian Weng's Blog
On the negative side, the model can learn a lot of social biases. A few of the example are listed below -
- If asked, “man is to computer programmer as a woman is to X” and the system answer x=homemaker [Reference]
- The same paper has other similar examples e.g. "father is to a doctor as a mother is to a nurse"
- People in the United States have been shown to associate African-American names with unpleasant words (more than European-American names), male names more with mathematics and female names with the arts. [Reference]
Conclusion
This was all for this post. We will continue word-embedding in the next post too. But there we will do the hands-on.
Although we discussed all the important points regarding Word-embeddings, still there are a lot of things that you should look into to gain a deeper insight. For that, go through the references provided in the post.
You can also check few additional blogs on the topic,