



Introduction
In this post, we will understand the approach that we need to take if we want the Gradient of any Node with respect to any other Node in a Tensorflow graph.
It's ok if you don't understand Tensorflow Graph. For this post, just keep in mind that a Neural Network in Tensorflow/Keras is a graph consisting of Nodes(Operation) and Edges(Data).
The most common need to get the Gradient of a Node w.r.t to another Node is when we do the Backpropagation step during training. We also used it in our Blog on CNN Visualization using Gradient-CAM [Check here]
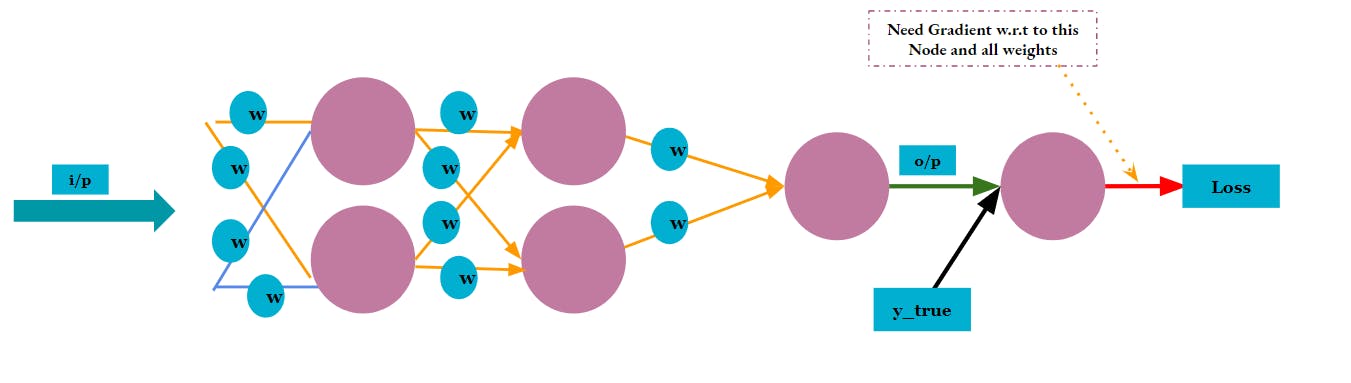
Below is a depicting of a typical Neural Network. As mentioned, we need the Gradient of the Loss w.r.t each weight.
How can we calculate the Gradient
There are 3 key ways to calculate the differentiation -
Finite-Difference - This is the traditional way to calculate the difference for any point for any function using the formula of slope i.e. $$f'(x) = \lim_{\delta\to 0}\frac{f(x+\delta)-f(x)}{\delta}$$
This approach will require a full pass of the neural network every time. Also, the delta must be almost equal to zero otherwise it will have inaccurate results. If you will keep the delta too small then it might get a round-off error as the value decimal value to overflow the float size
Symbolic/Analytically - we can calculate the required Gradient for any function using the simple chain rule and using the known derivatives e.g. $$f(x) = xcos(x)$$ $$=> f'(x) = cos(x) - xsin(x)$$
Again, this technique will be incompatible with Neural Network which prefers to work with Tensors of float. Also, this is computationally inefficient considering the fact that every Network is unique and modern networks are too big for this approach. Lastly, this technique doesn't work with loop, benching and recursion
Automatic Differentiation- This is not a new technique in itself but it fits a wrapper of programming technique over chain-rule of the derivative. This is also called as Auto-Diff to differentiate it from manual approaches. It has two different ways to achieve the derivative. Let's understand both for this sequential expression- $$ x_1, x_2 \xrightarrow{log} {x_3}; x_3, x_4 \xrightarrow{sqrt} {x_5} ; x_5, x_6 \xrightarrow{sine} {y}$$
Forward-mode Auto-Diff - In this mode, while moving forward with the calculation, we also calculate the derivative of individual result and connect using the chain rule at the end. e.g. in the above expression, let's say we have to calculate the derivative of y w.r.t x1. So, we will keep accumulating the intermediate derivatives i.e. $$\frac{\partial x_3}{\partial x_1} ; \frac{\partial x_5}{\partial x_3} ; \frac{\partial y}{\partial x_5}$$ In the end, we can get the desired result by simple multiplication.
With this approach, we can overcome the issues mentioned for previous approaches but with this approach, we need a full pass for each variable i.e. x1. In a typical Neural network, we have millions of weights, so this approach will be very inefficient.
Reverse-mode Auto-Diff - In this mode, we don't target the derivative w.r.t to any specific variable but we save all the outputs and derivatives for each step in the forward pass step. Then in the reverse pass, we use that values to calculate the desired derivative using the chain rule.
With this approach, we can calculate the derivative of output w.r.t. any number of intermediate variable(weights). On the down-side, this approach needs a lot of memory to save( record) all those intermediate values and steps. It also needs appropriate planning so that we only record step/variables along a particular path instead of all possible paths in the whole network
You can read more on it - [ Wikipedia] and in this [ Paper].
Tensorflow uses Reverse-mode Automatic differentiation approach.
Let's calculate using Tensorflow
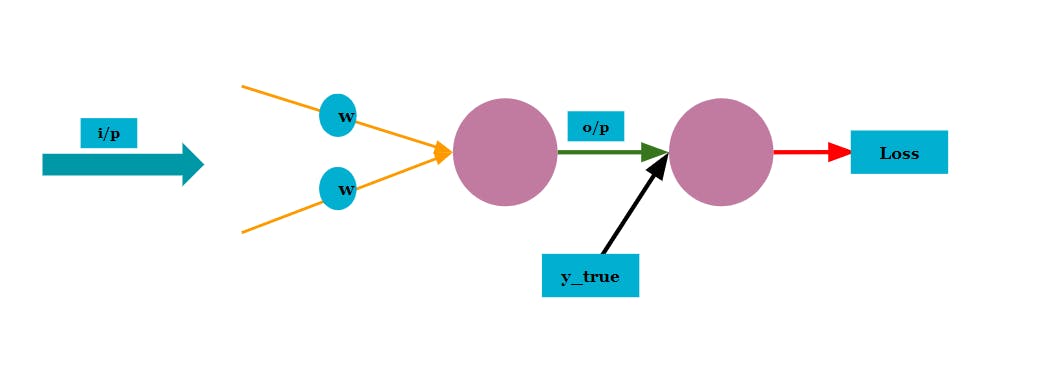
Now we fully understand how it is calculated. So, let's use the Tensorflow API and calculate it for a toy Graph [See below image]
import tensorflow as tf
input = tf.constant([[1.0,2.0]])
weights = tf.Variable([[0.25],[0.15]])
output = tf.linalg.matmul(input, weights)
# Loss - MSE
y_true = tf.constant(0.75)
loss = tf.math.sqrt(tf.math.subtract(tf.math.square(y_true), tf.math.square(output)))
The above snippet is a simple implementation of the Graph shown in the previous image. Now, let's add the Tensorflow GradientTape in this code.
input = tf.constant([[1.0,2.0]])
weights = tf.Variable([[0.25],[0.15]])
y_true = tf.constant(0.75)
with tf.GradientTape() as tape: #1
output = tf.linalg.matmul(input, weights)
# Loss - Squared Diff
loss = tf.math.squared_difference(y_true, output)
gradients = tape.gradient(loss, weights) #2
gradients
Code-output
<tf.Tensor: shape=(2, 1), dtype=float32, numpy=array([[0.39999998], [0.79999995]], dtype=float32)>
Code-explanation
#1 - We need to initiate a "with" context with GradientTape. It makes Tensorflow aware that it has to calculate the Gradient of all the nodes used in the code within the "with" context. This is the point we discussed in the previous section that we need a way to control which steps to record and which ones to ignore. We are achieving that using the "with" context
#2 - Then, we can simply get the Gradient of any output node w.r.t to an input Node. Since TF GradientTape has recorded and saved all intermediate outputs and derivatives.
Rules to keep in mind
- By default, GradientTape only watches a Variable not Constant. But there is a provision to force this
- The tape is automatically erased immediately after we call its gradient() method, so we will get an exception if we try to call it again. Here also, we can force it to act otherwise.
- We can't calculate the Gradient of a vector/Matrix w.r.t. another vector/matrix. It must be a Scaler value w.r.t to a Vector/Matrix. It will result, the sum of the gradients of each target
- The tape can't record the gradient path if the calculation exits TensorFlow e.g. using Numpy
- Try to keep the code within the "with" context as lean as possible
Let's see another snippet for these points.
input = tf.constant([[1.0,2.0]])
# Will not work if "tape.watch" is not added
weights = tf.constant([[0.25],[0.15]]) #1
y_true = tf.constant(0.75)
with tf.GradientTape(persistent=True) as tape: #2
tape.watch(weights) #3
output = tf.linalg.matmul(input, weights)
# Loss - Squared Diff
loss = tf.math.squared_difference(y_true, output)
gradients = tape.gradient(loss, weights)
gradients_copy = tape.gradient(loss, weights) #4
gradients_copy
Code-explanation
#1 - We defined the weights as Constant, it will not return the Gradient if this Constant not placed undertape.watch. You may try it by commenting #3
#2 - Addedpersistent=True, this will force the tape to not clear its content after first call totape.gradient
#3 - Put the weights undertape.watch( )
#4 -Called thetape.gradient( )again, this will work because the tape was initialized aspersistent=True
Let's train the toy network
Since we have got the Gradient of the Loss w.r.t to the weighs, so we can simply train the Model using the very basic concept of Gradient Descent i.e.
$$w = w - learning\_rate * Gradient$$
Let's take 3 data points and run a loop on them.
data = tf.data.Dataset.from_tensor_slices([[5.0,2.0], [3.0,3.0], [4.0,1.5]])
weights = tf.Variable([[0.55],[0.75]],shape=[2,1])
y_true = tf.data.Dataset.from_tensor_slices([0.75,0.5,0.4])
lr = 0.01 # Learning rate
dataset = tf.data.Dataset.zip((data,y_true)) # Zipped the two tensor to loop
for data, y_true in dataset:
with tf.GradientTape() as tape:
output = tf.linalg.matmul(tf.reshape(data,[1,2]), weights)
loss = tf.math.squared_difference(y_true, output)
gradients = tape.gradient(loss, weights)
weights.assign_sub(tf.multiply(lr,gradients)) # Applied the Gradient Descent
weights # Final trained weights
Code-output
<tf.Variable 'Variable:0' shape=(2, 1) dtype=float32, numpy= array([[0.02995202], [0.47385702]], dtype=float32)>
The above code snippet is self-explanatory. If you are not aware of TensorFlow Data API, then you may take a quick look into the official guide [Here]
For more insights on GradientTape, check the official guide for it, [Here]
For advanced concepts i.e. Higher-Order derivative, Derivative for tensor targets/tensor Source, etc. check this official guide [Here]
Summary and conclusion
With this post, we understood different ways to calculate the Derivative. Then we derived into the working of Auto-diff.
Then we learnt the Tensorflow implementation i.e. GradientTape to achieve the derivative of output for any input weights. Try to go through the references mentioned in different sections.
With all this knowledge and code, you should be comfortable to build a custom neural network for any purpose.
We will use this knowledge in our blog to "Visualise a convolutional neural network"[Link].