




Introduction
When we have a very high Cardinality for a Feature or a group of Features. Entity Embedding is an elegant way to get a lower-dimensional representation of the Features.
The most simple example would be the Latitude/Longitude representation of a large number of zip code though in this case, we know this relation from our general knowledge.

Entity embedding not only reduces memory usage and speeds up neural networks compared with one-hot encoding, but more importantly by mapping similar values close to each other in the embedding space reveals the intrinsic properties of the categorical variables. [From the paper]
Embedding is a very famous concept in text analysis[Word embedding], where each text is represented using a set of Numeric features and the encoding should end up learning the underlying relationship e.g. in the embedded Lion, Tiger might be closer to each other but a bit part from Cow, Dog.
Needless to say that this relationship is based on a contextual setup. The Closeness and difference will depend on the context. e.g. two zip code may be close in the context of Revenue while the same zip code may look far when the context is of reported crime.
You may read this blog on word embedding if you want to dive very deep Link
The key goal is to learn a continuous space for the discrete Feature. This will not only ease the model's training process but also it can be reused for a similar scenario at some other place.
How to get it
The whole process is very simple. We create a Neural Network with an additional layer that acts as a mapping for the "Feature-to-be-embedded" to Embedding space.
The output of the embedding layer is concatenated with all the remaining Features. After this Layer, it is just like a simple Neural Network. The embedding weights are initialized with a random value and learned by backpropagation.
Take a look at the depiction in the diagram. We may create separate embeddings for each feature Or may club multiple features into one as shown in the image.
The size of the Embedding i.e. count of Neurons is a Hyperparameter to tune.

Now, Let's try to understand the neural network for the task.
In the diagram below, the green rectangle is the Label Encoded values of the Features which we want to embed. The Green Circle is the Embedding Layer. The blue pentagon is the concatenated layer.
The outputs of the Embedding layer will be the embedding for a particular input.
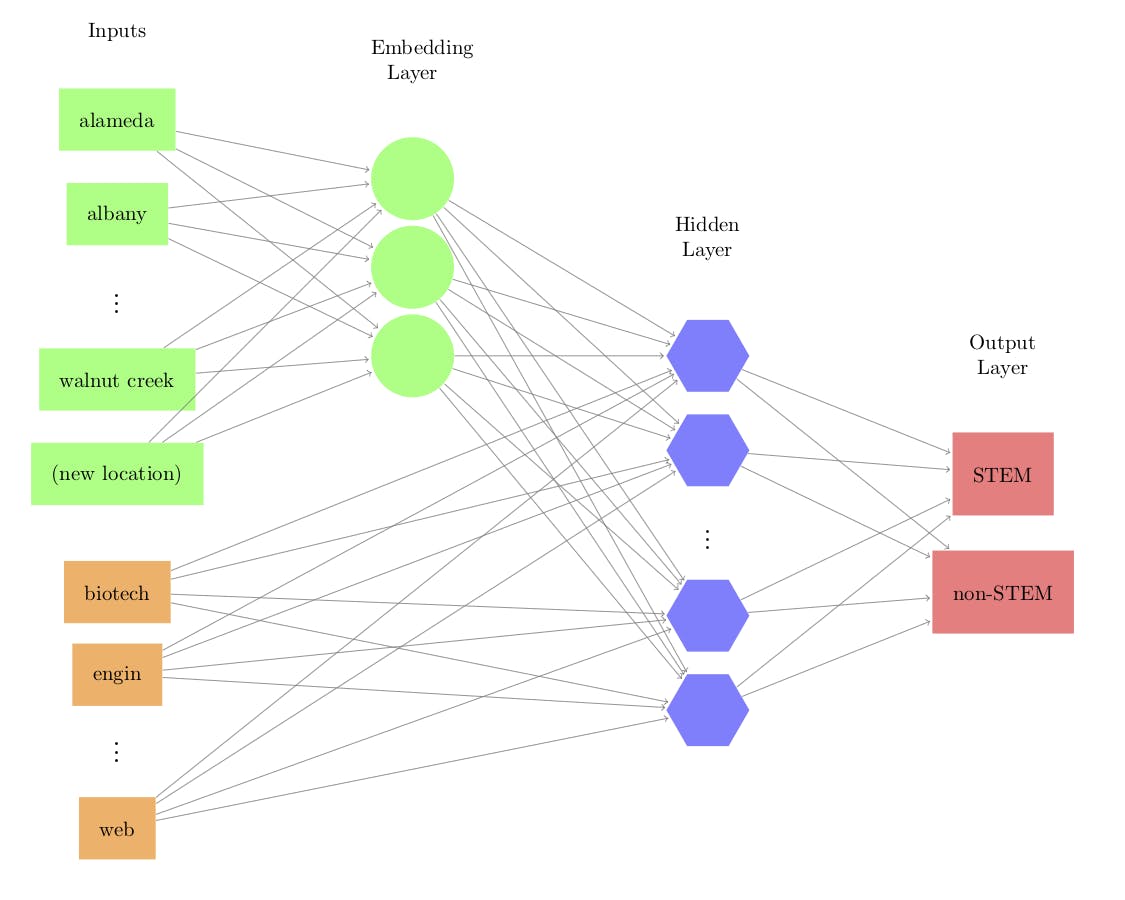 Image source - Feature Engineering and Selection: A Practical Approach for Predictive Models, Max Kuhn and Kjell Johnson
Image source - Feature Engineering and Selection: A Practical Approach for Predictive Models, Max Kuhn and Kjell Johnson
Keras Embedding Layer
Keras Embedding Layer will do all the work needed as per the above explanation. It takes the embedding size and the vocab-length as parameters. Length of Input is the number of words but in our case, every Feature value has a length of 1. This is more useful in a Text Data analysis setup where features values are sentences.
tf.keras.layers.Embedding(
input_dim,
output_dim,
.
.
.
input_length=None
)
input_dim: Integer. Size of the vocabulary, i.e. maximum integer index + 1.
output_dim: Integer. Dimension of the dense embedding.
input_length: Length of input sequences, when it is constant. This argument is required if you are going to connect Flatten then Dense layers upstream
Let's see the code
import tensorflow as tf
from tensorflow import keras
embedding_size = 25
embed_input = embed_input = layers.Input(shape=(1)) #Green Rectangle
embed_layer = keras.layers.Embedding(max(x_train_embed)+1, embedding_size, input_length=1)(embed_input) #Green Circle (embed_layer) #1
embed_layer = layers.Flatten() #2
#embed_layer = keras.layers.Reshape(target_shape=(embedding_size,))
other_input = keras.Input( shape = (x_train_other.shape[1])) #Orange Rectangle #3
model = keras.layers.concatenate([embed_layer, other_input], axis=-1) #Blue Pentagon
drop_rate=0.0;hidden_count = 5
for i in range(hidden_count):
model = keras.layers.Dense(embedding_size+20, activation='relu')(model)
model = keras.layers.Dropout(rate=drop_rate)(model)
model = keras.layers.Dense(1, activation='linear')(model)
model = keras.layers.Dense(1,)(model)
model = keras.Model(inputs=[embed_input, other_input ], outputs=model)
model.compile(loss='mean_squared_error', metrics=['mean_squared_error'])
model.fit([x_train_embed, x_train_other], y_train,
epochs=25, validation_split=0.2)
Code-explanation
#1 - x_train_embed is the label encoded data.embedding_sizeis 25 for our case
#2 - Default output shape:(batch_size, input_length, output_dim). We flattened the 1x25 2-D since we are concatenating with a similar Input. You may useReshape Layertoo.
#3 -This is the Input from all other remaining Features
Moel is traine now. Let's pull the Embedding vectors from the Network.
model_emb = tf.keras.Sequential()
model_emb.add(keras.layers.Input(shape=(1)))
model_emb.add(model.layers[1]) #1
#model_emb.summary()
model_emb.predict([81])
df = pd.DataFrame(model_emb.predict(pd.unique(x_train_embed))[:,0,:],
columns=[embed_col+str(i) for i in range(embedding_size)])
df_map = pd.concat([df, pd.Series(pd.unique(x_train_embed))], axis=1) #2
Code-explanation
#1 - We have created a small Network to predict the Embeddings
#2 - Predicted for all the values and then concatenated with the unique values to create a ready-to-use map
Why it works
It works in a context i.e. what is the Data represent and what is the Target. The data we get can have too many Categorical values but it might be quite possibly the in some unknown space these may be represented by smaller Domesnions i.e. 4 or 5 etc.
A very common example can be data related to geography e.g. Countries. They might be equivalent to their distance from the Equator Or their GDP. So with such representation, they can be simply encoded in smaller dimensions.
Another example can be, let's say we have 12 Cardinal Feature representing each month and a Target representing a Tourist count. Definitely, the tourist count will have a smooth transition from Nov-Jan even though the Year changes. The Neural Network must learn a mapping that can represent this relation e.g. Dec is at a similar distance to both November and January.
The task in hand is to find the optimum number of Dimensional that can represent the underlying patter in the best possible manner
For that, we rely on the Neural Network Learning process. If the loss is decreasing then Embedding is moving in the correct direction from the starting point which was a random value
Conclusion
Let's review a few of its limitation first,
- Very first limitation is to use a Neural Network. Not everyone would like to bring on a new technological idea to solve an encoding challenge.
- Need tuning of the embedding dimensions
- Loss of Interpretability
Despite its limitations, the idea is very versatile. It is the foundation on which text-data analytics has achieved all its successes. In text-data, it works like a pre-trained Network. Offers not just dimensionality reduction but also infuse sufficient information into the data. This was all we have for this post. You may use this concept when you have very high Cardaniity features. There can be other approaches too. Check out the Categorical encoding post Link