




Introduction
Hello Friends, the title of the post may sound counter-intuitive to many of you since you might be habitual of listening to a lot on the internet about how to master ML in 21-days etc.
It might look simple if you just skim it quickly but if you sit with an intention to solve a real-problem or participate on Kaggle or even try to answer questions on Stackexchange, you will realize the gap even though you consider yourself complete with the required courses.
In case you have not tried any course/tutorial, then the very first challenge in front of you is to assimilate such a large volume of courses and content.
On top of all this, if you see a message similar to this tweet, confusion raises to the next level.
Let's see another stat that adds further to the confusions. This is an excerpt from State Of AI annual publishing.
Source - State of AI Report 2020, Slide#80
Supply is not being fulfilled is connected to the quality of the supply. We will come back to these images in the conclusion part of the post. Let's move to the next section to figure out why it so.
A complex inter-disciplinary subject
The very first challenge anyone can face with Machine Learning is the task of grasping so many disciplines.
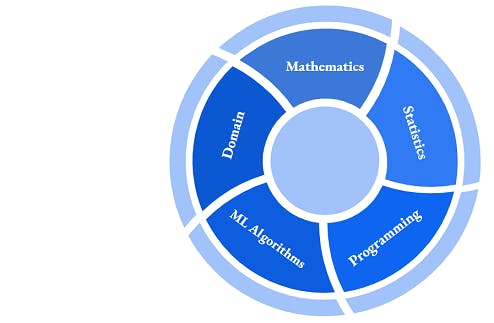
- Mathematics is mixed throughout the ML space i.e. the working of Models. You will need a basic understanding of Linear Algebra, Probability and Calculus(Deep Learning).
- Statistics is the subject on which machine learning is based on. Many of the basic models are based on pure statistics and almost all of the models have their root in Statistics. If you know the underlying Statistics, then you feel very confident about the learning and enjoy the whole process. Though you may move into Modelling with a little of Maths and Statistics.
- Programming - There are many views out there that you might not need programming to be a Data Scientist but that's will be true in a limited scope. There is no one-fit-all model or approach. What it means is that you need a lot of engineering with ML API and Data analysis API i.e. Numpy. and this is without considering the post Modelling work i.e. Deployment, MLOps etc. You will need a programming hand for all these activitis.
- ML Algorithms - As we said earlier, there is no one-fit-all model or approach, so you need to understand the pros and cons of different models and accordingly you can try it. This particular part will require the above-mentioned knowledge of Mathematics and Statistics. Other than understanding the models you will need the art of Feature engineering, which itself is a very abstract subject and can be learnt mostly by doing.
Imagine studying all these from bottom to top. It's almost equivalent to 2 years of engineering. The good news is that you can do things in a shorter time if you curate the learning properly especially Mathematics, Programing and Statistics. So, the summary of the section is to find and follow a fine-grained course that has sufficient focus on programming.
Data and Domain
The domain is the Industry domain to which the data belongs to. Data will be generated only through a process e.g. Movie review, Twitter, Medical images, Sales data etc. Each of these data belongs to the specific domain e.g. Finance, Pharma, Manufacturing etc.If we have the expertise of the domain then it might ease the modelling part e.g. you many easily figure out why a particular group of data behaving differently with the model.
But we can not do much on it as it is completely dependent on your work experience and also your inner interest.
Data has other aspects too i.e. Type and Size. Data can be Tabular, Image, Text, Sequence, Image etc. All of these will bring a new type of learning requirement and most of the time a new modelling strategy e.g. a simple Neural Network will become a Convolutional Neural Network for Image data and Recurrent Neural Network for text data and on top of that, you will be introduced to the concept of Transfer-Learning, Word-embedding etc.
Data size brings another complexity to the problem i.e. merging of two different entity i.e. Large Dataset(I am avoiding the term Big Data) and ML modelling. You can't keep these as two separate functions i.e. one team will do all the data part and then the ML team will do the modelling. Why it will not work because the ML guy will have to inspect i.e. trying different models, Feature engineering, Tuning etc., on this large dataset and the step which should take 1 minute will start consuming 2 Hours. So, you have to figure out a new set of Library implementation, Software engineering etc.

Bonus point - ML research is moving very fast esp. for Text and Images. So, this becomes an additional task to keep up sync with the Research.
How to proceed
We have a detailed post on the list of books and tutorials to follow. Check it here
In this post, we will just summarize the key steps -
- Start early, I believe from the second semester of your bachelor. You will have an ample amount of time.
- If you are already in a job, you don't have a similar choice. So focus on your will-power.
- Commit at least 10 hours each week. Don't expect any magic before one year.
- Learn Python, Numpy to a decent level. Check the suggested post for books references.
- Balance concept and code. Check the suggested post for books references.
- Participate in Kaggle and read the good solution to get the noble idea
- Follow Industry leaders on Twitter
Skipping Statistics/Mathematics
You might be tempted to skip these two portions and may move ahead to a decent level even without them. But this will hamper your growth in terms of scalability of learning e.g. you will start skipping those great sources of knowledge that uses a lot of these pieces of stuff.
Programming
You may receive a bit different suggestion on this aspect too. But you should only avoid it when you are sure what you are doing i.e. there are fields that might not be using a very large amount of data or it may be working purely in the domain of Statistical testing.
Conclusion
With the last section, we are done with this post. The idea was never to intimidate you but it was to make you aware. Learning only the very basics pieces is good to generate interest but it will not land you to a place you might be aspiring for.
There are many positive pieces too,
- AI is going to stay here with new forms and Architecture every few years.
- Whatever be the technology, it will have to knock the door of AI after a certain level of Maturity e.g. "Using AI for X"
- Investment is intact in this space, check this excerpt from AI Index 2021 survey.
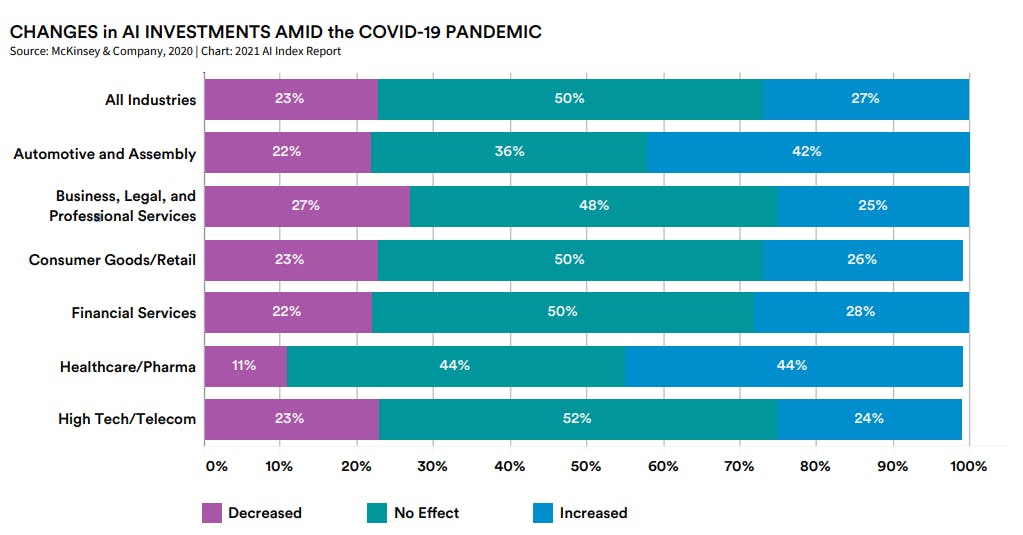 Now, you can connect the above stats with the stats shown at the beginning i.e. about the job not getting fulfilled. Companies are expecting people to come beyond the "Hello world" ML stuffs i.e. very simple Datasets and scenario.
Now, you can connect the above stats with the stats shown at the beginning i.e. about the job not getting fulfilled. Companies are expecting people to come beyond the "Hello world" ML stuffs i.e. very simple Datasets and scenario.
One the first image, Andriy is correct in his claim but his expectation with Scikit-Learn is not appropriate. Please read the full-tweet thread Here.