




Introduction
Hello friends, in this post we will continue the last topic i.e. Word Embeddings. Here we will program rewrite our Sentiment Analysis code with Pre-trained word embedding. You can check the last code Here. In that post, we learnt to program our own embedding using Backpropagation.
In this post we will train with,
- Word2Vec embedding
- GloVe Embedding
- FastText Embedding
Training with GloVe
Let's start with GloVe first.
We will use the code of Post#02 of this series(Check Here) and take that forward. Below is a summarized depiction of our previous approach and the current approach,
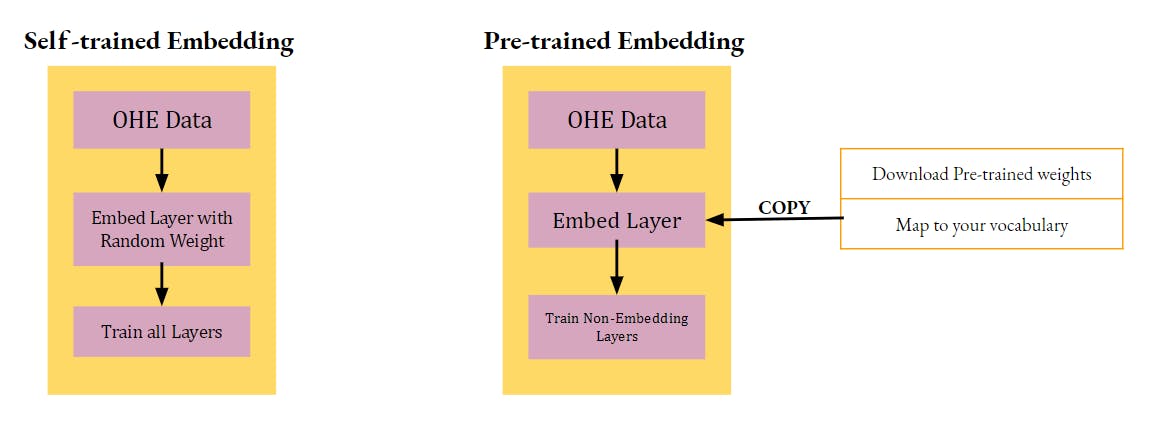
We will not rewrite the code of the previous post. So please check that out first.
Let's code the Pre-trained embedding part,
!wget http://nlp.stanford.edu/data/glove.6B.zip #1
file_name = "/content/glove.6B.zip" #2
from zipfile import ZipFile #3
with ZipFile(file_name, 'r') as zip:
zip.extractall()
Code-explanation
#1 - This is the URL for the GloVe embedding file
#2 - Local path of the downloaded zip file
#3 -Unzipped the file
! cat "/content/glove.6B.50d.txt" | head -1000 | tail -1
Result
attention -0.084238 0.53053 0.12816 -0.28886 -0.18125 -0.205 -0.096976 0.070474.....
Code-explanation
We have viewed one line of the file to see its structure. It's a simple space-separated value of all the dimension. The "Word" is the first token of each line
Let's read the file line by line and create a dictionary mapping for each word to its embeddings.
word_to_embeddings_map = {}
file = "/content/glove.6B.100d.txt"
with open(file) as file: #1
for line in file:
values = line.split()
word = values[0] #2
embed = np.array(values[1:], dtype='float32') #3
word_to_embeddings_map[word] = embed
Code-explanation
#1 - Open the file and read it in for-loop
#2 - Split it on "space". First token is the "word" rest all is the embeddings
#3 -Convert the embedding into a numpy array and assign it to the dictionary
Now we will get all the words of IMDB movie review dataset and then map its word to GloVe embedding using the above dictionary.
embedding_dim = 100
word_index = keras.datasets.imdb.get_word_index() #1
embedding_matrix = np.zeros((vocab+1, embedding_dim)) #2
for word, i in word_index.items():
embedding_vector = word_to_embeddings_map.get(word) #3
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Code-explanation
#1 - Get the word to Idnex map of IMDB review dataset
#2 - Create a matrix of the size of embedding and out vocab
#3 -Loop on each word of the IMDB index and get its GloVe mapping and place it in the above matrix
Now the last step becomes very simple. Use the Keras word embedding layer and replace its weight with the above embedding and make it non-trainable.
dropout = 0.5
neurons = 128
model = keras.models.Sequential([
keras.layers.Embedding(embedding_matrix.shape[0], embedding_dim, input_shape=[None],mask_zero=True), #1
keras.layers.Bidirectional(keras.layers.GRU(neurons, return_sequences=True, dropout=dropout)), #2
keras.layers.Bidirectional(keras.layers.GRU(neurons, return_sequences=True, dropout=dropout)),
keras.layers.Bidirectional(keras.layers.GRU(neurons, dropout=dropout)),
keras.layers.Dense(250 , activation='relu'),
keras.layers.Dropout(rate=dropout),
keras.layers.Dense(1, activation="sigmoid")
])
model.layers[0].set_weights([embedding_matrix]) #1
model.layers[0].trainable = False #2
optimizer = keras.optimizers.Adam(learning_rate=0.002)
model.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model.fit(x_train_ohe,y_train, epochs=15, validation_data=(x_test_ohe,y_test), batch_size=256)
Code-explanation
#1 - Set the weights with the word embeddings
#2 - Freeze the Layer to make it non-trainable
Training with word2vec
Now we can simply repeat the above steps for any other embedding. So, we will not place the full code for word2vec. We will only add the code to download and read the file.
!wget "https://tfhub.dev/google/Wiki-words-250/2"
embed = hub.load("https://tfhub.dev/google/Wiki-words-250/2")
embedding_dim = 250
word_index = keras.datasets.imdb.get_word_index()
embedding_matrix = np.zeros((vocab+1, embedding_dim))
for word, i in word_index.items():
embedding_vector = embed([word]).numpy()[0]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Code-explanation
All other parts of the code is quite trivial and self-explanatory.
Training with fastest
Now everything should be quite simple. You can repeat the same for fasttext too. Below is the downloadable URL. Fasttext
Fine tuning the pre-trained
You might have observed that the test accuracy is around 80%. Since pre-trained embeddings are trained on a large and generic corpus, so not necessarily it will fit exactly to our dataset.
But we can fine-tune the pre-trained embedding with a very small Learning rate just like we do in a CNN pre-trained model.
This will improve the test accuracy to ~85% very easily.
model.layers[0].trainable = True
optimizer = keras.optimizers.Adam(learning_rate=0.0001)
model.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model.fit(x_train_ohe,y_train, epochs=5, validation_data=(x_test_ohe,y_test), batch_size=256)
Conclusion
This was all we have for applying any pre-trained word embedding to your tokens.
You can extend it to -
- Any other dataset e.g. Fakenews dataset.
- Try bigger dimensions of the pre-trained models
Dimension of the embedding will be like any other Hyper-parameter i.e. start with the smallest and try a bigger one till you are satisfied with the computation/score trade-off.
In the next part of the series, we will understand and code "Language Modelling".