



Introduction
This article serves as a follow-up to our previous post on the topic [ Link ]. In the earlier article, we delved into the essential terminologies associated with OpenAI, such as Tokens and Prompts. Additionally, we learned the fundamentals of using the OpenAI API to interact with a model through Python.
Towards the end, we introduced two intriguing use cases that we'll be exploring further in this post. We will now dive into the practical aspects of these use cases, providing you with the necessary code to build a Q&A bot based on local documents, as well as a video summarization tool.
By the end of this article, you will have gained a comprehensive understanding of how to apply OpenAI's API for these specific applications. Not only will you be able to utilize these tools in your own projects, but you'll also be equipped with the knowledge to adapt them for various other purposes.
Q&A Bot from your own Content
In this section, we will build upon the foundations laid in the previous tutorial to create a Q&A bot using the OpenAI API, designed to answer questions based on your own content. By following the steps and techniques we discuss, you'll be able to develop a powerful tool that can help you quickly access relevant information from your documents
Familiarity with OpenAI concepts, such as tokens and prompts, is necessary, as covered in our previous tutorial. Additionally, it would be beneficial to have a fundamental knowledge of Python programming, as the code examples will be presented in this language.
Bonus
We will also incorporate a language detection and translation module to accommodate Hindi queries, in addition to English ones, even though our knowledge base is exclusively in English. By integrating this functionality, our Q&A bot will be able to process queries in Hindi and English.
Concept
Let's dive into the concept using a simple block diagram

Step#1 - First, generate an embedding for the user's query using OpenAI's available API, such as GPT-3.
Step#2 - Next, create embeddings for all the documents in your knowledge base. If you have larger documents, consider generating embeddings for individual sections.
Step#3 - Then, perform a similarity analysis between the query and each document to identify the most relevant match.
Step#4 - Finally, input the user's query and the matched document as a prompt to the OpenAI API, such as the text-davinci-003 model, to generate a context-aware response.
Code
Let's dive into the code of the above design-flow. I try my best to make everything looks very intuitive, so would be the code pieces.
This is our corpus
corpus=''' Ayushman Bharat, a flagship scheme of Gover......" # [ Link ]
# Imports and Model
COMPLETIONS_MODEL = "text-davinci-002"
EMBEDDING_MODEL = "text-embedding-ada-002"
openai.api_key='xxxxxxxxxx'
max_len=1000
splits=len(corpus)//max_len #1
cor_list=[corpus[i*max_len:(i+1)*max_len] for i in range(splits)] #2
document_embedding_list = [get_embedding(cor) for cor in cor_list] #3
len(document_embedding_list)
code explanation
#1 Define and splits a length to split the corpus into small chunks
#2 Create a corpus list which contains the chunks as a list
#3 Create embedding for each chunks
@backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def get_embedding(text, model=EMBEDDING_MODEL): #1
result = openai.Embedding.create( model=model,input=text)
return result["data"][0]["embedding"]
def vector_similarity(x, y): #2
return np.dot(np.array(x), np.array(y))
def order_document_sections_by_query_similarity(query, contexts) : #3
query_embedding = get_embedding(query)
document_similarities = sorted([
(vector_similarity(query_embedding, doc_embedding), doc_index) for doc_index, doc_embedding in enumerate(contexts)], reverse=True)
return document_similarities
code explanation
#1 Get the embeddings for any text
#2 Utility function to calculate distance between two numpy array
#3 Function to calculate similarities and sort the doc based on similarity
def detect_language(query): #1
return langdetect.detect(query)
# Function to convert user query to English
def translate_func(query, from_language, to_lang): #2
prompt=f"Translate the following sentence from {from_language} to {to_lang} using only {to_lang} characer set: {query}"
english_query = call_openai_api(prompt)
return english_query
def get_prompt(best_corpus, query): #3
prompt = f"""Answer the question truthfully and only using the provided text. Also, take care of the rules.
Rules :
Rule#1 - If the answer is not available in the text, say "I don't know".
text: {best_corpus}.
Question:{query}
A:"""
return prompt
code explanation
#1 A utility to detect language since we will ask question in Hindi and English
#2 Utility function to Translate between a source and target language
#3 Utility function to draft the prompt using user's query and the best corpus
def the_bot(query): #1
# labguage map to short desc
lang_dict={"en":"English","hi":"Hindi"}
# Detect language of query
src_language = detect_language(query)
to_lang="en"
# Convert query to English if necessary
if src_language != 'en':
query = translate_func(query, lang_dict[src_language], lang_dict[to_lang])
best_doc_id=order_document_sections_by_query_similarity(query, document_embedding_list)[0][1]
best_corpus=cor_list[best_doc_id]
prompt = get_prompt(best_corpus, query)
response=call_openai_api(prompt)
if src_language != 'en':
response=translate_func(response, lang_dict[to_lang], lang_dict[src_language])
return response #, best_doc_id
# Main code
query="आयुष्मान योजना का संक्षिप्त विवरण दें?"
query="How much is the maximum benefit amount ?"
print(the_bot(query))
code explanation
#1 Detect language | Translate into English | Get best corpus
#1 Build prompt | Get response from text model | Translate to Hindi if requires
#2 Sample queries in Hindi and English
Output


Use case II - Summarizing a YouTube video
Having become well-acquainted with the OpenAI API, let's dive straight into the process of creating a YouTube video summarizer. We will quickly outline the block diagram and provide the necessary code to build this handy tool. To accomplish this task, we will be leveraging the Whisper API from OpenAI, which is specifically designed for handling audio-related tasks.
Bonus
The same code can be adapted for summarizing videos from any source by simply modifying the download function. You can also use it for local videos or audio files by skipping the relevant functions. This flexibility makes the code versatile and applicable to a wide range of media sources.
Concept
Let's dive into the concept using a simple block diagram
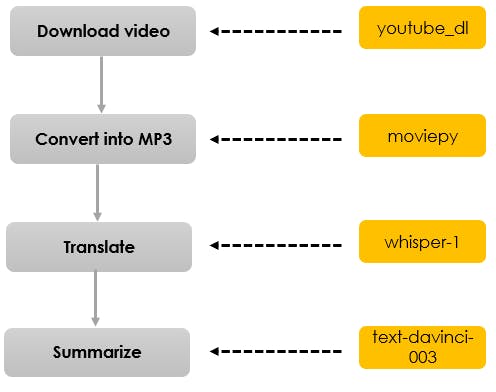
Code
import os
import youtube_dl
def download_video(url):
# Download the video using youtube_dl
ydl_opts = { 'format': 'worst', # specify the lowest resolution available
'outtmpl': '%(title)s.%(ext)s' } # specify the output filename }
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
info_dict = ydl.extract_info(url, download=False)
file_full_path = ydl.prepare_filename(info_dict)
file_name = os.path.basename(file_full_path)
# rename file
os.rename(file_name,file_name.replace(" ","_"))
file_name=file_name.replace(" ","_")
return file_name
def convert_to_mp3(url):
file_name=download_video(url)
# Convert the video to audio using moviepy
videoclip = VideoFileClip(file_name)
audioclip = videoclip.audio
audio_file_name=f"{file_name[:-4]}.mp3"
output_path = os.path.join(root_path, audio_file_name)
audioclip.write_audiofile(output_path)
# Delete the video file
videoclip.close()
audioclip.close()
os.remove(file_name)
return audio_file_name
def get_transcript_list(url, context, speaker):
# Slit into chunks
import soundfile as sf
audio_file_name=convert_to_mp3(url)
audio, sample_rate = sf.read(audio_file_name)
# PyDub handles time in milliseconds
chunk_size_min = 20 * 60 * sample_rate
chunk_list = [audio[i:i+chunk_size_min] for i in range(0, len(audio), chunk_size_min)]
transcript_list=[]
for i,chunk in enumerate(chunk_list):
# Expot chunk as mp3
tmp_file_name=f"{audio_file_name[:-4]}_{i}.mp3"
sf.write(tmp_file_name, chunk, sample_rate)
# Call OpenAI API
open_file= open(tmp_file_name, "rb")
transcript = openai.Audio.transcribe("whisper-1", open_file, prompt=f"{context} by {speaker}")
transcript_list.append(transcript['text'])
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
transcript_list=' '.join(transcript_list)
return transcript_list
max_tokens=500
def call_text_api(prompt):
return openai.Completion.create(
prompt=prompt, max_tokens=max_tokens,
model=COMPLETIONS_MODEL)["choices"][0]["text"].strip(" \n")
def get_prompt(i,context,speaker,transcript_list,token_len):
speech_context=context
speaker=speaker
ask='Please create the summary of the message'
other_req=f"""
1. Your response must be in bullets
2. Summary must have maximum 10 bullets and minimum 7 bullets
3. Keep the bullet as it will be on a slide simple and just the message"""
prompt = f"""{speech_context} by {speaker}
speech : {transcript_list[i*token_len:(i+1)*token_len]}
your task : {ask}
Take care of these points : {other_req}
Your response :"""
return prompt
def create_summary(url, context, speaker):
token_len=2000
transcript_list=get_transcript_list(url,context, speaker)
chunk_cnt=len(transcript_list)//token_len+1
for i in range(chunk_cnt):
prompt=get_prompt(i,context,speaker,transcript_list,token_len)
response=call_text_api(prompt)
return response
url="https://youtube.com/shorts/KMRL5YYvqc8?feature=share"
context="Money savings trade-off"
speaker="Robert Kiyosaki"
print(create_summary(url, context, speaker))
Output

Going forward
With the completion of the final code segment, we have successfully accomplished two significant tasks that were quite challenging just a few months ago. The total cost of these operations was approximately $0.2 or ~16 INR, with the majority of the expense attributed to Whisper's usage fees. As more competitors enter the market and these technologies become more commoditized, it's likely that the costs will decrease, making these powerful tools even more accessible in the future.

Let's take a moment to consider some limitations and potential areas for improvement in our current implementation. Although there may be numerous shortcomings in the existing code, we will focus on two primary concerns:
The code lacks a structured approach and is not built around a specific framework.
If we have thousands or even millions of document embeddings, determining the most appropriate method for searching and matching these embeddings becomes a significant challenge.
Addressing these issues will be essential for future enhancements and scalability.
Solutions
In recent times, several frameworks have emerged to facilitate the development of applications based on APIs from well-known vendors. LangChain, for instance, is gaining traction among AI enthusiasts as a framework designed to create applications powered by language models.
The industry has also acknowledged this challenge, and numerous new frameworks and cloud-based systems are being developed to address these needs. One such recommendation can be found in a Twitter thread by "@ NirantK" highlighting the growing interest in solving these problems. Below is a summary image from the same thread.
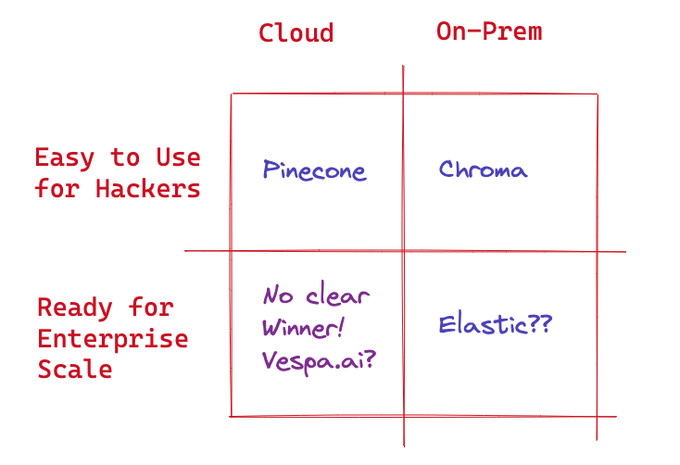
That's it for this post.
In my upcoming blogs, I will explore using LangChain and at least one VectorDB to implement the code we've discussed here. Stay tuned for more exciting insights and demonstrations of these powerful tools in action.